Created time
Apr 3, 2024 06:50 AM
date
status
category
Origin
summary
tags
type
URL
icon
password
slug
本文由 简悦 SimpRead 转码, 原文地址 vlog.jiejaitt.top
有趣的技术实践分享
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
本文将详细剖析端到端语音识别的基本知识,读完本文你将了解:
- 什么是端到端语音模型
- 模型里有哪些必要结构
- 训练是怎么进行的
- 推理是怎么进行的,和训练有什么区别
- 都有哪几种解码方式,他们的意义和区别
- 端到端有什么优势和弊端?
- 延伸阅读
- 长音频如何推理
- 开源框架那家强
1. 什么是端到端
端到端语音识别是区别传统语音识别的一种框架,并逐渐成为一种趋势。传统语音识别一般分为声学模型与语言模型,声学模型负责将音频序列转化为音素序列,常见的音素比如汉语拼音、英文音标等,语言模型则负责将这些音素序列转化成文字序列。声学模型和语言模型在训练时并不需要耦合,可以独立训练,传统语音模型的劣势在于需要有发音字典,需要有音素的标注。端到端模型就是克服了这一点,直接将音频序列转化为文字序列。
2. 模型的基本结构
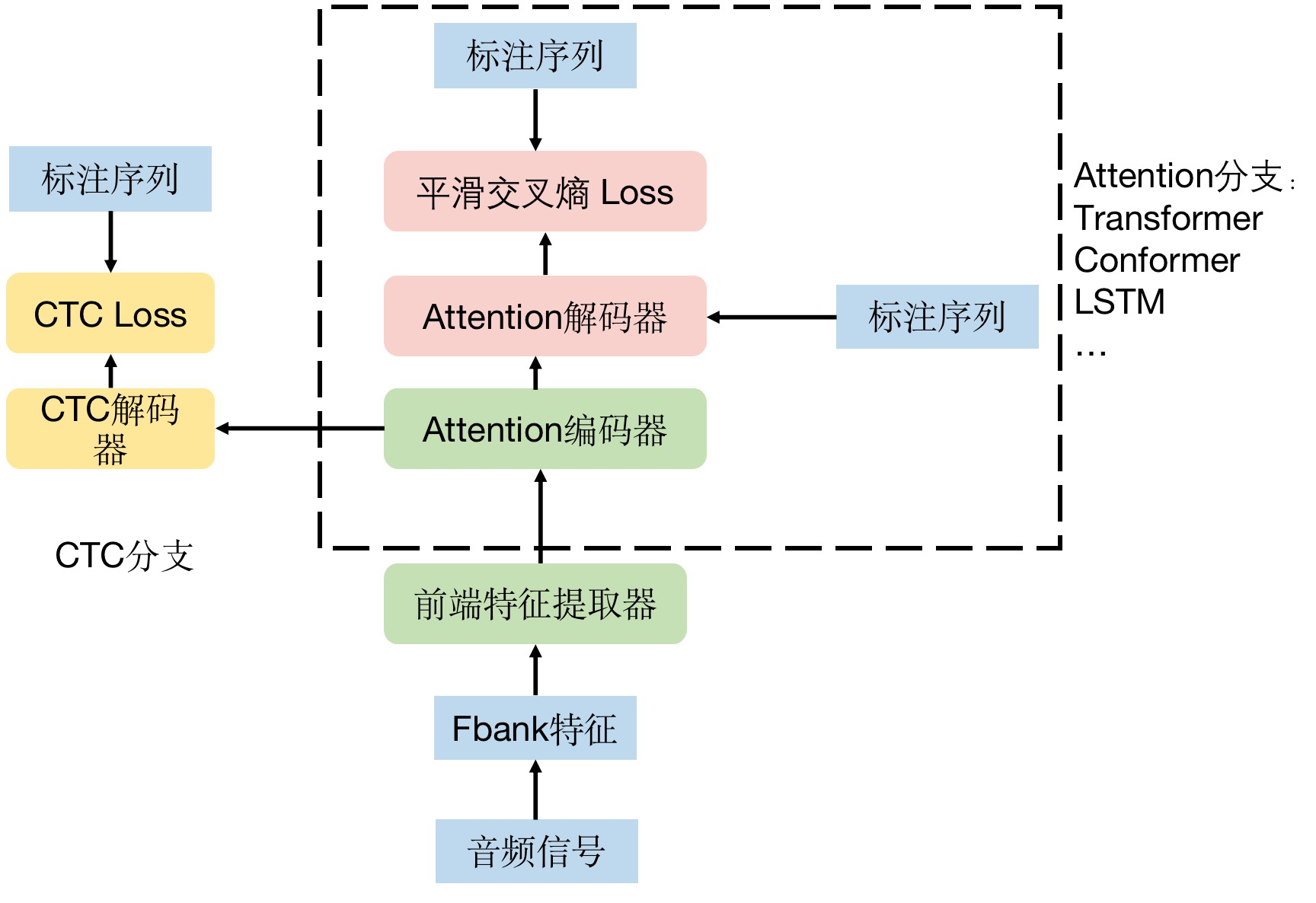
一般的端到端语音模型结构中,大致可以分成三个部分,分别是前端特征提取器、CTC 分支和 Attention 分支:
- 前端特征提取器:一般是若干层卷积,其目的是在时间维度上降采样,从而减少计算开销。
- Attention 分支:包含 attention 机制的一系列模型,比如 Transformer、Comformer,甚至之前的 LSTM,可以任意选择。通常用平滑交叉熵损失约束。
- CTC 分支:其结构上通常是一个全连接层,将 encoder 的特征转化为每个字的概率,用 CTC 损失约束。
如果要实现语音识别的基本功能,这三个结构并不都是必须的,比如前端特征提取器,但是它可以减少计算开销,很多框架和开源代码中都会有这一步。其次 CTC 分支和 Attention 实际上有其中一条就可以实现语音识别的基本功能。但是有实验表明这两条支路的两种损失一起训练模型可以得到更好的效果。需要注意的是,尽管训练时,两条支路都会用到,但是推理时一般只会用到其中一条支路(除了 wenet 里实现的 attention-resocring 解码机制)
对于 Attention 分支,涉及 Transformer、LSTM 这类模型,因为并不局限于某一种模型,且本身细节较为庞杂,有许多优秀的文章进行过介绍,因此不打算在这里细究其内部细节,只抽象出编码器和解码器这个模块,重点是要讲清楚在语音识别中,数据和特征的流动方式。至于 CTC 分支和前端特征提取器,较为特殊且在语音识别中很常用,下面将做进一步介绍。
2.1 前端特征提取器

前端特征提取器常见的操作是对语谱特征 fbank 做两次 stride=2 的卷积,同时将通道数扩展到 256,再进行 reshape 和全连接层映射,将特征长度统一为 256。这也是后面 Attention 分支里所采用的特征长度。经过这么一通计算,时间轴的长度约为原来的 1/4,这样可以降低后面 attention 的计算开销。
2.2 CTC 分支
下图中移动的部分就是 CTC 分支,它以 Attention 编码器的输出特征作为输入,通过一个全连接层将 256 维的特征映射成字典大小的向量,再进行 softmax 归一化,得到每个字的预测概率。
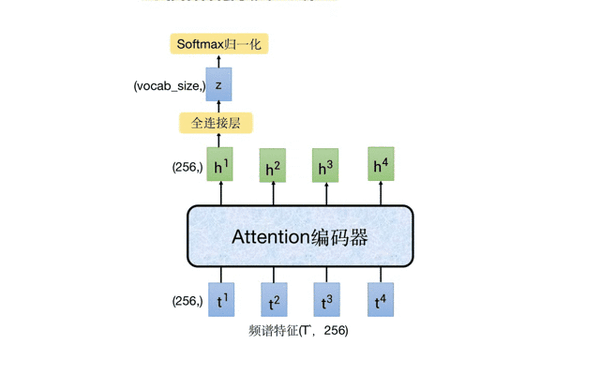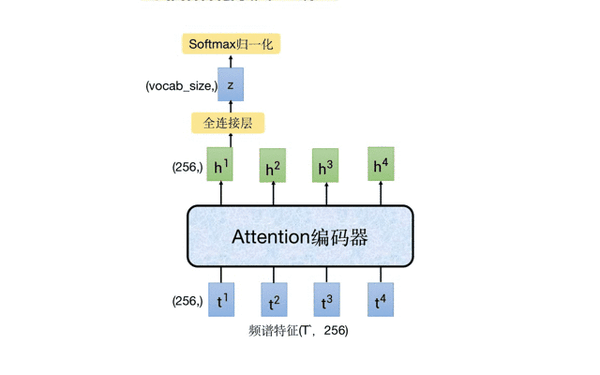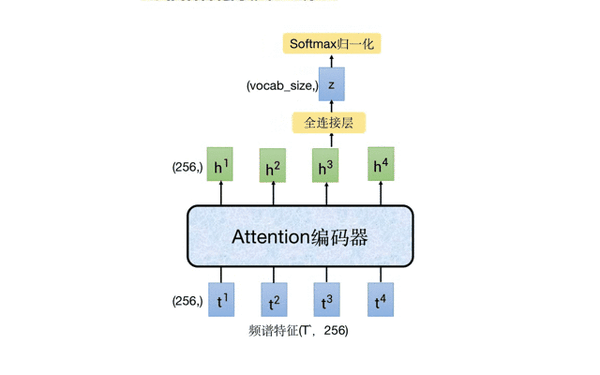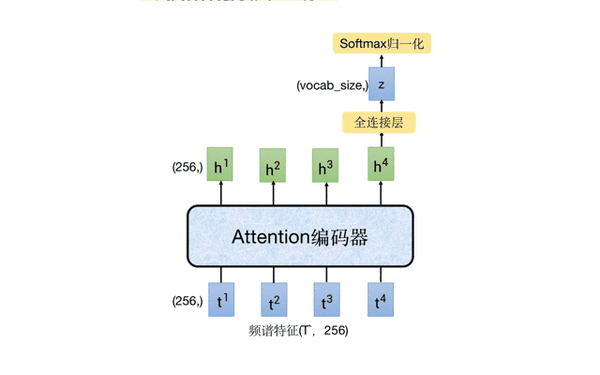
这里我们来 “算一笔账”,我们假设提取 fbank 特征时的步长时 10ms,那么 1 秒的音频,其语谱特征就大约 100 帧,经过前端特征提取器进行 4 倍降采样后,大约是 25 帧。因为 attention 编码器的输入和输出维度保持一致,都是 25*256,这意味着 1s 的音频,CTC 可能会解码出 25 个字,这显然是不合理的。下面会详细介绍 CTC 是怎么进行训练和推理的。
- 模型如何训练
3.1 CTC 分支
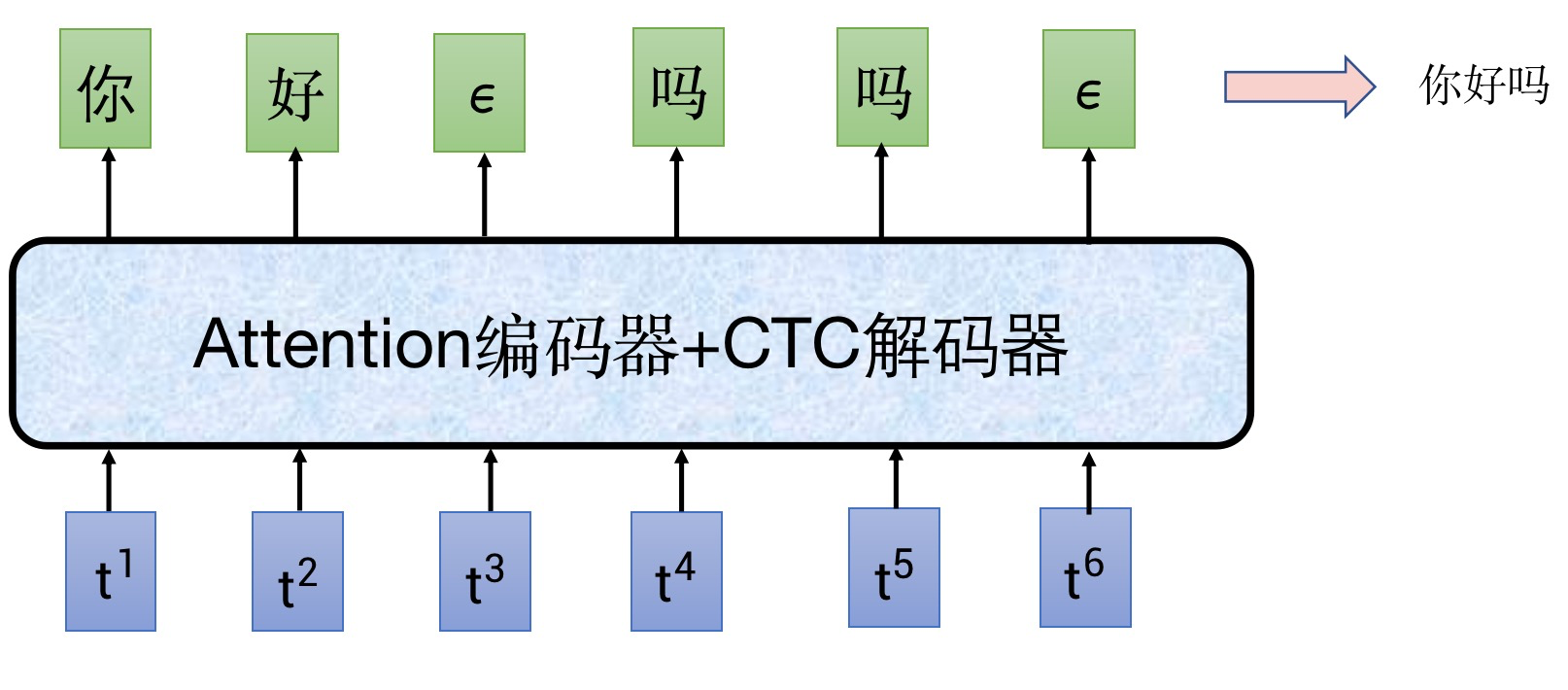
在带 CTC 分支的语音识别框架中,一般会在字典中加入一个特殊的字符——空,下面用ϵ 来表示空字符。人在说话的时候,每句话之间是有空隙的,并且每个人说话的语速不同,每个字之间有不同的空隙,引入空字符ϵ 之后,实现了模型对这类空隙的建模。这时候联想回前面说的 1s 似乎要输出 25 字,问题就能得到一定程度的解决,大部分时候是可以输出空字符的,并不需要输出有意义的字。
这时候再来思考一个问题,我们说话 1s 说不了几个字,但是 1s 对应 25 帧,那么每个字的发音都会占据很多帧,可能会连续几帧都识别成一个字,那怎么办?这就引入 CTC 分支解码时的规整方法(有些地方也称之映射):
- 删除所有ϵ 字符
- 合并连续出现的相同字符
如下图所示,ctc 原始解码出的原始序列——“你好ϵ 吗吗ϵ”,按照规整方法,将两个空字符去掉,并且两个 “吗” 合并,最终得到结果 “你好吗”。(需要注意的是,由于图的大小有限,这里只写了六帧作为示意,正常语速说一句你好吗,是远远不止六帧的,空字符会比图中密集许多,只有偶尔一两帧输出有意义的文字,这也被称为 CTC 的尖峰效应)
——这个时候又有新问题了,这玩意要用什么 loss 约束,怎么约束呢?
——这还不简单,这不就是字的分类问题,可以用多分类的交叉熵损失?
——问题是,你需要对每一帧输出进行计算,你有每一帧标注吗?
——额,可以有,以前的方法,确实是要有具体到帧的标注。
——如果没有呢?
这其实就是一个对齐问题。就刚刚举的例子来说,会有很多的对齐方式,即有很多种情况都可以合法地规整(映射)成 “你好吗”,比如:
- ϵϵϵ 你好吗
2. 你 ϵ 好 ϵϵ 吗
- 你你你 ϵ 好吗 CTC 损失函数的基本思想如下:假设 CTC 输出的原始序列为 Z,目标文本序列为 Y,只要找到所有可以规整成标注序列 Y 的原始序列 Z,计算这每个原始序列 Z 的概率之和,这个概率和就是 CTC 分支预测为 Y 的概率,我们希望这个概率越大越好,所以我们只需要以最大化这个概率和为目标函数,就可以实现 CTC 分支的训练,并且回避掉对齐的问题。
当然这里仍然存在一个问题,要怎么找到能规整成目标序列 Y 的所有原始序列 Z?最简单的方法当然是穷举,假设字典大小为 N,输入序列和输出的原始序列长度均为 T,那么穷举所有情况需要到达 N^T 这个量级,这显然是不太科学的,因此在实现中需要引入动态规划算法来节省计算量。(这不是三言两语讲得清楚,先挖个坑)
除此之外,CTC 还存在一个局限性,就是每个时刻间的概率是相互独立。这明显是不合理的,因为说话是存在上下文联系的,某一时刻预测的字,应该会对下一时刻预测的字产生影响,但从 CTC 分支的结构却无法体现这种上下文关联,为此有人提出一种改进结构 RNN-Transducer 来解决这个问题。另外,下面要讲的 Attention 分支则完全没有这个问题。
3.2 Attention 分支
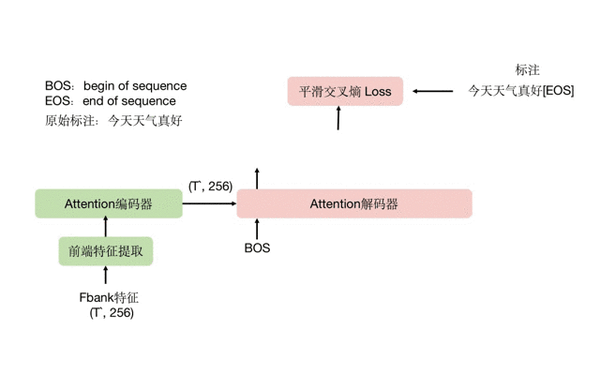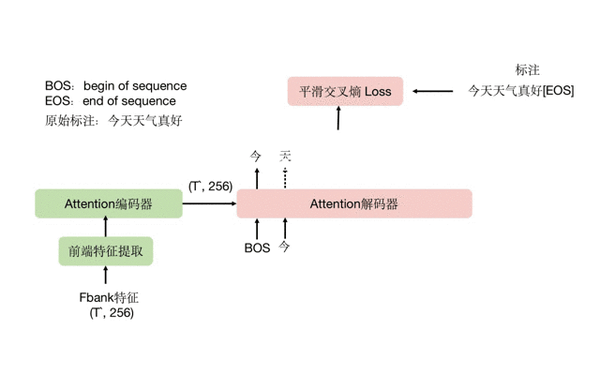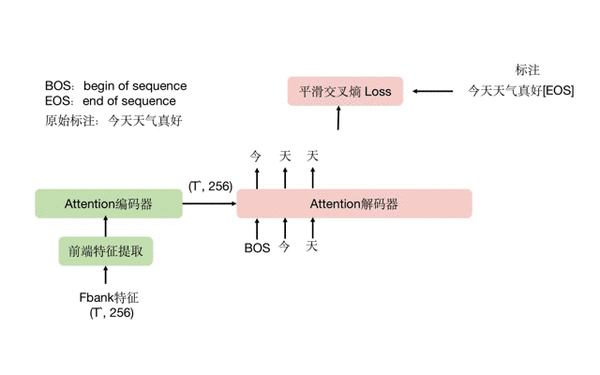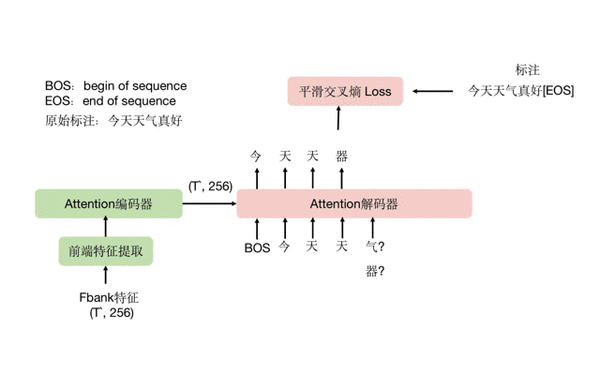
这里以 Transformer 类的模型为例,解码器以文本作为输入,同时也会接收编码器输出的特征,进行 cross-attention 操作。先简单说下推理时,attention 解码的方式,一开始我们给解码器送入一个 BOS 起始符号,希望解码器结合编码器送过来的音频编码特征,预测出这段音频的第一个字 “今”,模型成功预测出 “今” 字,将它重新放回解码器的输入,希望解码器预测出下一个字 “天”,一直这样循环下去,直到最终预测出句子终止符号 EOS 为止。这套过程也称为自回归解码,是 attention 解码的一大特点,它的好处是能更好地结合已经预测的上文文本,去推测下文信息,句子的通顺程度和字错率通常都更好。
但是如果是训练,则可能出现一种情况,如果解码器输出的字是错的,比如 “天气” 的 “气” 预测成了 “器”,那么在预测下一个字时,放到解码器的输入层是“器” 还是 “气” 呢?尤其是模型刚开始训练时,可以预见几乎每个字都是错,以错字为已知信息放到解码器输入,岂不是错上加错?这就涉及两种不同的训练思路:
- 用 “气”。也就是甭管解码器预测的上一个字是什么,只从标注中拿到正确的那个字放到下一个时刻的输入。这种方法叫做 Teacher-Forcing。
- 用 “器”。就是模型认为上一个时刻是什么字,就把这个字作为下一个时刻的解码器输入,这种方法叫做 Schedule-Sampling。
这两种方法各有优势,Teacher-Forcing 的优势有两点:
- 减少了误差累计,模型训练起来更容易收敛 2. 如果 Attention 分支采用的是 Transformer 这类允许序列并行计算的模型,由于在训练时不关心上一时刻输出什么,所以完全可以一次性将一整句话送入解码器,即 [BOS,今,天,天,气,真,好],而对应的标注应该是 [今,天,天,气,真,好,EOS]。这就可以实现并行计算,而避免了一个字一个字往外崩的串行计算了。
如果你对 Transformer 不是很熟,可能会有疑问,一整句话作为输入,那么在预测第 i 个字时,岂不是已经可以看到第 i+1 个字是什么呢?甚至 i 后的所有字都可以看到。其实是在 transformer 在进行 attention 操作时,会通过 mask 盖住后面的信息,这样就实现了训练与推理时的一致性。
但是 Teacher-Forcing 也有一个弊端,就是他没有模拟实际推理时会出现的上文出现了错字,下文要如何预测的问题,因此训练和推理仍然存在不一致的问题。
至于 Schedule-Sampling,很明显它和推理是一致的,它可以很好地模拟推理时出现错字的情况,因此具有更好的鲁棒性。但是其缺点也是很明显的,就是更难训练,收敛更慢,并且由于只能串行计算所以效率不高。
有人也提出了一种折衷的方法,以结合两者的优点,就是在训练时以一定概率选择要用 “气” 还是 “器”,即用真实标注还是解码器预测的上一时刻输出。这个概率要怎么定呢?基本的原则就是在训练初期,以更高的概率选择真实标注,等到模型具备一定的预测能力,再以更高的概率去选择解码器上一时刻的输出,即使该输出是错的。具体可采用的衰减策略比如线性衰减、指数衰减等。
- 模型如何推理
前面讲述了模型如何训练,但其实在 CTC 分支和 Attention 分支中都简要提到了它们怎么在测试时是怎么推理的,这一小节将具体展开其中的细节。
4.1 CTC 分支
4.1.1 贪婪解码 (greedy search)
对于 CTC 分支,我们可以在每个 t 时刻都取概率最大的字,得到一个原始序列,再删除该序列的空字符,合并相邻的相同字符,规整成最终的输出,这种解码方式叫做 CTC 贪婪解码,这种解码方式的速度很快,但是贪婪只是局部最优,而不是全局最优。
4.1.2 波束搜索 (beam search)
为什么说贪婪只是局部最优,而非全局最优,这里先看一个例子,假设字典只有三个字符 {a,b,ϵ},序列长度为 2,按照贪婪搜索,t1、t2 时刻概率最大的字符均为ϵ,所以得到的原始序列为 \epsilon$$\epsilon,经过规整,两个空字符都被去掉,最终解码出来是一个空文本。
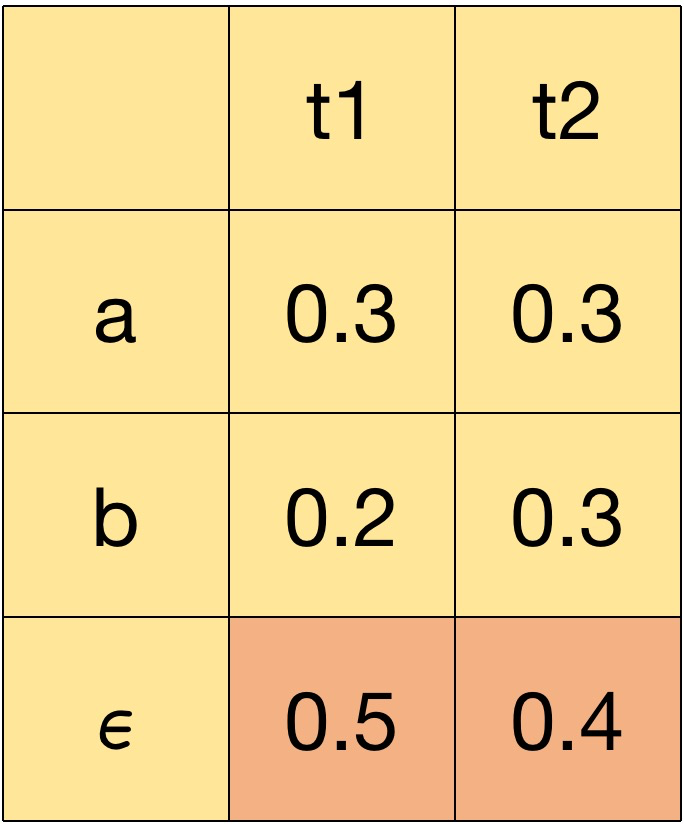
但是这个概率矩阵是解码成空文本的概率最大,联想前面所说的会有很多种原始序列 Z 都可以规整成同一个序列 Y,那么预测为序列 Y 的概率应该是所有可以合法规整成 Y 的序列 Z 的概率之和。
因此,由于字典有三个字符,且只有两个时刻,因此可能输出的序列 S 为 a、b、ab、ba、ϵ,他们的概率分别是:
P(S=a) = p(aϵ) + p(ϵa) + p(aa) = 0.3 * 0.4 + 0.5 * 0.3 + 0.3 * 0.3 = 0.36
P(S=b) = p(bϵ) + p(ϵb) + p(bb) = 0.2 * 0.4 + 0.5 * 0.3 + 0.2 * 0.3 = 0.21
P(S=ab) = p(ab) = 0.3 * 0.3 = 0.09
P(S=ba) = p(ba) = 0.2 * 0.3 = 0.06
P(S=ϵ) = p(ϵ\epsilon) = 0.5* 0.4 = 0.2
从全局的角度,应该是解码成序列 a 的概率最大,我们单看 aϵ,ϵa 和 aa 的概率都小于 \epsilon$$\epsilon 的概率,但是他们都是规整成 a,他们的概率加起来就比 \epsilon$$\epsilon 要大,这才是全局的最优解。我们这里举的例子非常简单,给定序列长度 T 和字典大小 N,所有可能的排列组合有 T^N 个,这个搜索空间太大了,为了加速解码,可以在每个时刻只保留分数最高的 M 条路径,以大幅缩小搜索空间,又能带来比贪婪搜索更好的准确性。
具体的过程如下图,字典里仍然是 {a,b,ϵ} 三个字符,波束搜索的宽度为 3,即每时刻只保留分数最高的 3 条路径。
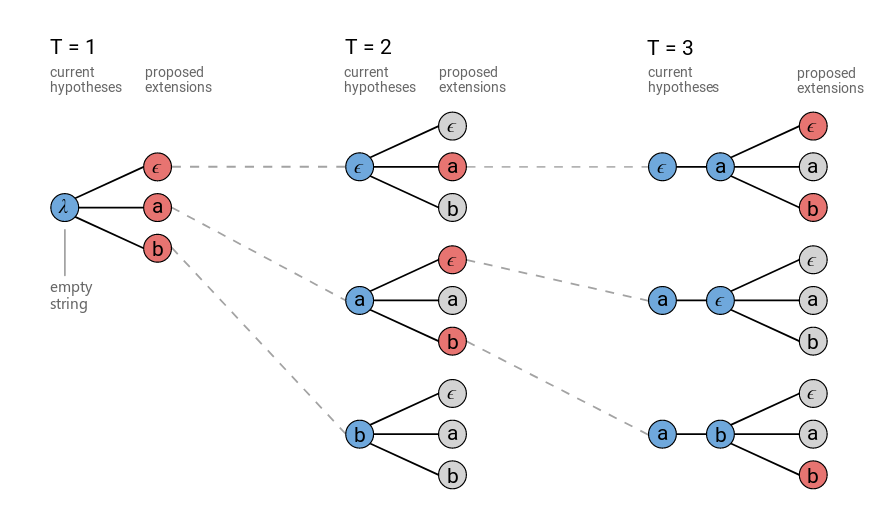
当 T=1 时,还没有历史预测字符,所以图中最左侧蓝圈是个空字符串λ 。然后看当前 CTC 输出的每个字的概率,由于字典大小为 3,波束搜索宽度也是 3,所以直接全取,得到三条路径,每条路径的当前字符串结果为ϵ,a,b。
当 T=2 时,先看蓝色圈,它表示的历史保留的三条路径,前面说了分别是 ϵ 、a、b。在当前时刻,CTC 会输出每个字的概率,和三条历史路径的分数相乘,总共有 3*3=9 种情况,会进行 9 次相乘运算,保留当前分数最高的三条路径,如红色圈所示,分别是 ϵa 、aϵ、ab。
当 T=3 时,和 T=2 时一样,蓝色圈表示历史保留的路径,同样又是 9 种情况,计算 9 次乘积,保留分数最高的三条路径 ϵaϵ 、 ϵab 、abb。
至此,波束搜索结束,再按照规整方法删除空字符,合并相邻的相同字符即可。可以看到,在每一步都只会进行 波束宽度 * 字典大小 次乘积运算。假如不是波束搜索,那么 T=2 时,暂时还是 3_3=9 种情况,只进行 9 次乘积运算,但是这 9 种情况都要保留,到了 T=3 时,就会扩展出 9_3=27 种情况,假如还有 T=4 就是 27*3=81 种情况... 也就是字典大小 N 的 T 次方。当然波束搜索也不是全局最优,但是至少比贪婪搜索有一定的优化。
4.1.3 前缀波束搜索 (prefix beam search)
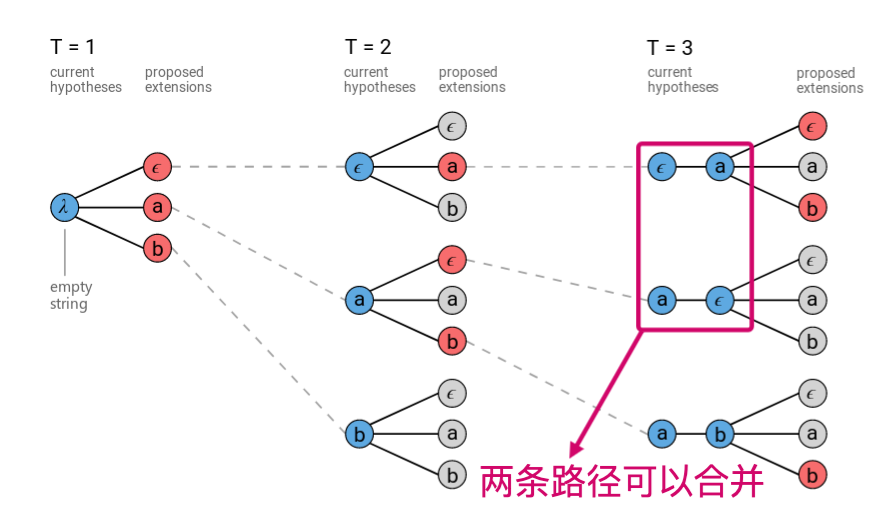
我们再来观察一下波束搜索的过程图,在 T=3 时,有两条历史最高分路径分别为ϵa 、aϵ,按照 CTC 的规整方法,它们都需要删除空字符,最后结果都是 a。这就意味着, 本来每一步就只保留 3 条路径,现在发现有两条路径规整后结果时一样,实际上只有两条不同的路径,这就使得搜索空间变相缩小了,路径的丰富度减小了。因此可以考虑在每一个时刻都进行规整,以合并相同的路径,并且能规整成相同结果的多个路径的分数需要叠加。这就是前缀波束搜索的基本思想。
前缀波束搜索的过程如下:
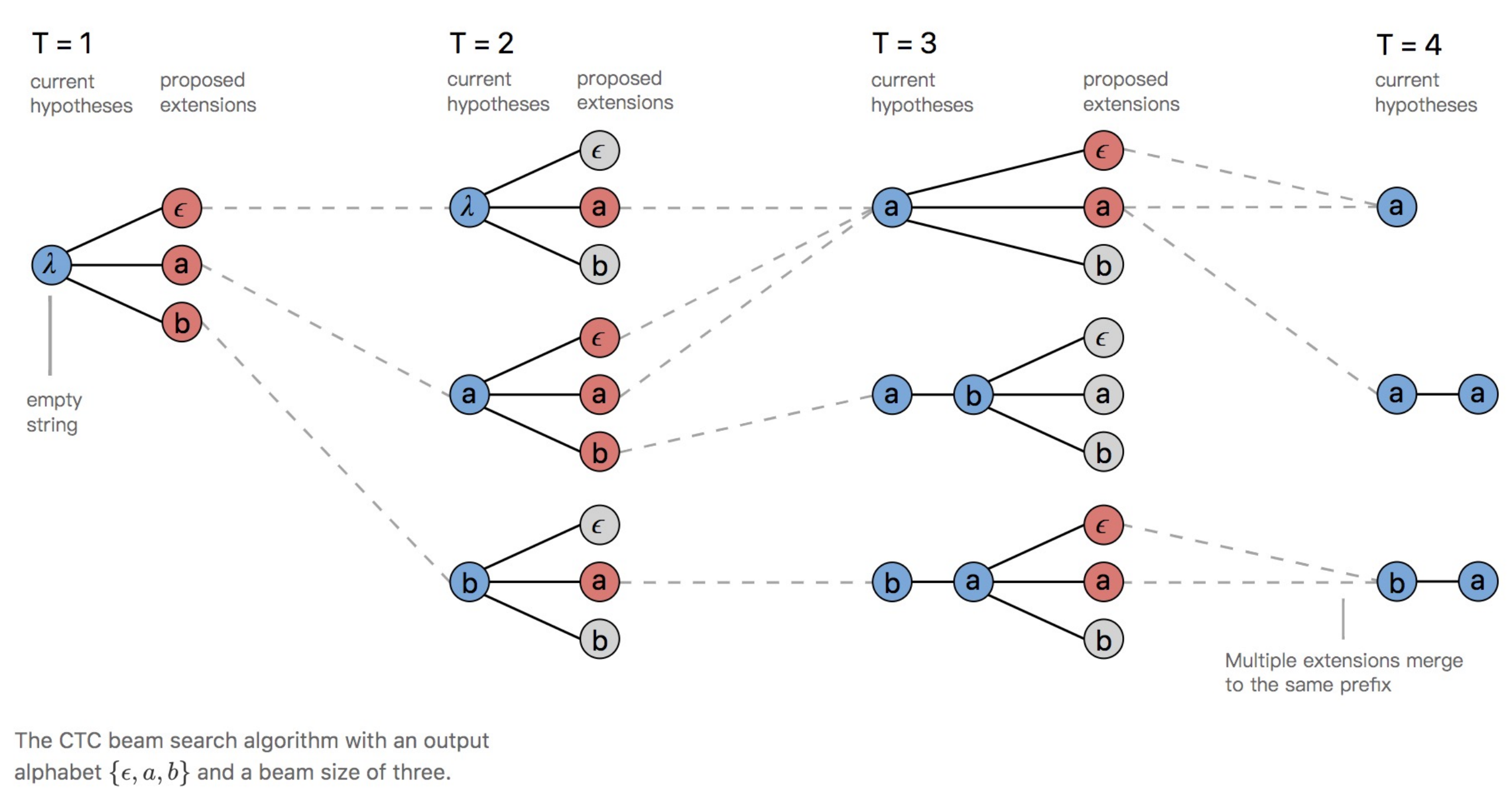
当 T=1 时,和前面波束搜索是一样的,不赘述
当 T=2 时,和前面波束搜索有两点不同:
- 最顶上的蓝色圈是 λ 空字符串,为什么?因为 T=1 时的其中一种路径 ϵ 是空,直接规整删除掉了,所以在这条路径依然是空字符串。并且可以观察到整个图的蓝色圈都没有 ϵ ,因为都是写的规整后的历史路径。
- 和波束搜索时一样,也是会有 9 种情况,也是要进行 9 次乘积运算,但是这 9 种情况里面, ϵa、aa、aϵ 都是会解码成 a,这三条路径的分数会相加,所以可以看到他们都汇聚到 T=3 时刻最顶上的蓝色圈 a;按照同样的道理,将 9 种情况里,将可以规整成相同结果的路径进行合并,分数叠加,保留分数最高的三条路径 a、ab、ba。
当 T=3 时,和 T=2 类似,仍然是 9 种情况,对他们进行规整合并,保留分数最高的三种结果。
至此,前缀波束搜索完毕。
无论是波束搜索还是前缀波束搜索,其时间复杂度都是一样的——T*N * 波束宽度。前缀波束搜索最终得到的结果路径数目,和波束宽度的值相同,波束搜索则可能小于这个数目,因为最终会有些地方可以合并。但是无论如何,语音识别最终应该只会输出一个结果,这么多条路径结果要怎么选呢?最常见的就是选择分数最高的路径,也可以送进语言模型等对这些备选结果打分,得到一个语言模型的评价分数,选出分数最高的,或是在加权分数取一个最高的。
参考文献
- CTC 波束搜索和前缀波束搜索部分:https://distill.pub/2017/ctc
未完待续。。。